2016/07/22
2020/05/04
R言語の便利なコマンド集【第2.5回】
【第1回】ベクトル・行列の作成と四則演算・要素の参照
【第2回】データ読み込みとデータの取り出し方
【第2.5回】Rで解析する上で知っておきたい便利なコマンド集 ←今ここ!!
【第3回】Rで線形モデルによる回帰分析
【第4回】Rでの自作関数の作り方・使い方
【第5回】グラフのプロットと画像保存の方法(回帰直線)【終】
※R言語入門のトップページはこちら
R言語では、本当に便利なコマンドがいくつもあります。頑張れば、知らなくても解析は出来たりしますが、知っておくと解析がはるかに楽になる、というような類のものになっております。ただし、一度に全部覚えるようなものではなく、実際に解析を行っているうちに徐々に覚えるというようなものです。
なので、今回は「へえ~こんなコマンドもあるんだ~。便利だね~」っていうようなスタンスで、ご自身のパソコンで軽くプログラムを流しながら読んでもらえればと思います。
目次
- 1 R言語の便利なコマンド
- 1.1 列数・行数をカウントするコマンド”ncol,nrow”
- 1.2 ”data$列名”で参照したい列をベクトルとして取り出す
- 1.3 要素の数をカウントするコマンド”table”
- 1.4 列名行名を見るコマンド”colnames,rownames”
- 1.5 同じものをたくさん並べるベクトルの生成”numeric,rep”
- 1.6 変数の型の変換”as.numeric,as.character”
- 1.7 変数の型の確認”is.numeric,is.character”
- 1.8 NA(欠損値)にまつわるコマンド
- 1.9 ベクトルの長さを調べるコマンド”length”
- 1.10 和集合、差集合、積集合”union,setdiff,intersect”
- 1.11 繰り返しのfor文
- 1.12 条件式のif文
- 1.13 その他数々の便利コマンド
- 2 まとめと復習用コピペプログラム
R言語の便利なコマンド
第2回で使ったデータをここでも使って説明していきます。ダウロードはこちら↓
ちなみにこんなデータでしたね。
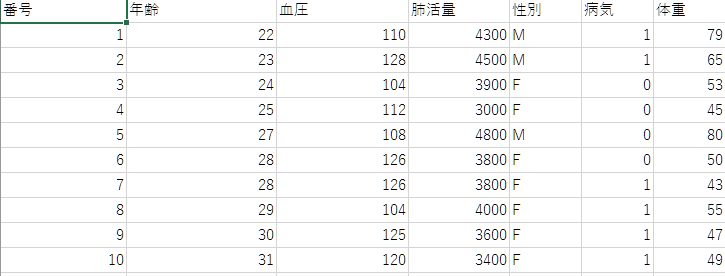
まずはデータを読み込みましょう!
df <- read.csv(“sample-data.csv”,header=T,row.names=1)
列数・行数をカウントするコマンド”ncol,nrow”
R言語では、読み込んだデータの列数や行数を一瞬でカウントしてくれるコマンドがあります。自分で数えたりしなくて良いので非常に便利ですね。dfの行数、列数をコマンドで確認してみましょう。
[1] 30
> ncol(df)#dfの列数
[1] 6
30行、6列の行列であるということが分かりました。
”data$列名”で参照したい列をベクトルとして取り出す
”データの入った変数$列名”で参照したい列をベクトルとして取り出すことができます。性別と血圧の列を見てみましょう。今回の場合は、dfにデータが格納されているので、
[1] M M F F M F F F F F M M F F M M M M F M F F M F M M M M F F
Levels: F M
> df$血圧
[1] 110 128 104 112 108 126 126 104 125 120 116 124 106 134 128 128 116 132
[19] 134 116 120 130 126 140 156 124 118 144 142 144
というようなプログラムになります。
要素の数をカウントするコマンド”table”
あるデータについて知りたい列についてのみ、要素数をカウントしてくれるコマンドが”table”です。例えば、あるデータの性別について男性、女性がそれぞれ何人いるかについて知りたい時に活躍します。
table(任意の列)をすることによって、その列について要素数をカウントしてくれます。また、列は何列でも入れられ、2列以上にすると非常に分かりやすい分割表形式で出力が行われます。dfの性別、性別と病気について実際のプログラムを見てみましょう。
15 15
> table(df$性別,df$病気)#性別と病気についてM,F、0,1が何人ずついるのかカウント0 1
F 8 7
M 4 11
列名行名を見るコマンド”colnames,rownames”
“colnames(),rownames()”を使えば、列名行名もR上で見ることができます。一々Excelデータを開かなくてもRで一目瞭然です、
[1] “年齢” “血圧” “肺活量” “性別” “病気” “体重”
> rownames(df)#行名
[1] “1” “2” “3” “4” “5” “6” “7” “8” “9” “10” “11” “12” “13” “14”
[15] “15” “16” “17” “18” “19” “20” “21” “22” “23” “24” “25” “26” “27” “28”
[29] “29” “30”
もし見たいデータが行列ではなく、ベクトルのときは行、列は関係ないので関数”names(ベクトル)”を使うようにします。
同じものをたくさん並べるベクトルの生成”numeric,rep”
例えば、0を100個並べたベクトルを作りたいときに、0を100回書くというような原始的なことをする必要はありません。R上ではちゃんとスマートなコマンドが用意されています。
numeric()を使えば0を好きな数だけ並べたベクトルを生成します。
また、rep(並べたいもの、並べたいかず)で好きなものを好きなだけ並べることもできます。
今回は0を15回並べてみましょう。
[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
> rep(0,15)#0を15回繰り返す
[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
変数の型の変換”as.numeric,as.character”
C言語などでもありますが、R言語の変数にも”型”というものが存在します。例えば、同じ”1”でもそれが数字なのか文字なのかで意味は全く異なります。Rがその”1”を数字として認識しているのか、あるいは文字として認識しているのかということです。数字として認識していれば、計算に使えますが、文字として認識している場合、計算に使おうとするとエラーが発生してしまうかもしれません。
もしRに文字として読み込まれた”1”を計算に使いたいのならば、それを数字として再度Rに読み込ませる必要があります。そこで今回のコマンドの出番ですね。
as.numericで数字型に変換。as.characterで文字列型に変換されます。
da.ch <- as.character(da)#daを文字列に変換
da <- as.numeric(da.ch)#da.chを数字に変換
変数の型の確認”is.numeric,is.character”
変数の型を確認するコマンドもあり、このように使います。さきほど作った変数daとda.chの型を確認してみましょう。
[1] FALSE
> is.numeric(da)#daが数字型ならTRUE
[1] TRUE
> is.numeric(da.ch)#da.chが数字型ならTRUE
[1] FALSE
NA(欠損値)にまつわるコマンド
NAとは欠損値のことです。解析する予定のデータは完全なデータであるとは限りません。例えば、一人だけ年齢のデータが抜けていたり、血液型のデータが取れなかったりと解析データには欠損値があることがあります。実は欠損値の処理は解析するうえで非常に大切な問題なのです。
そこで頻繁に使うのが、欠損値であるか調べる”is.na()”と欠損値を除く”na.omit()”です。使い方は単純、簡単であるので是非覚えておいてください。
あえて欠損値をいれた、yというデータを作ってコマンドを使ってみます。
> is.na(y)#NAかどうかを調べる
[1] TRUE FALSE FALSE TRUE FALSE
> na.omit(y)#欠損(NA)を除く
[1] 1 2 5
attr(,”na.action”)
[1] 1 4
attr(,”class”)
[1] “omit”
ベクトルの長さを調べるコマンド”length”
ベクトルの長さを知りたい時は”length()”を使います。zの長さを測ってみましょう。
z <- c(2,4,6,1,3,5)
length(z)
#lengthはベクトルの長さを測る
重複した要素を除く”unique”
重複する要素は除きたいときは”unique()”を使いましょう。実際に使うとこんな感じになります。
> unique(a)
[1] 1 2 3
和集合、差集合、積集合”union,setdiff,intersect”
Rでは二つのベクトルの差集合、和集合、積集合を取り出すコマンドも用意されています。二つの集合k,lを用意して使ってみましょう。
> l <- seq(2,20,by=2)
> k
[1] 1 2 3 4 5 6 7 8 9 10
> l
[1] 2 4 6 8 10 12 14 16 18 20
> union(k,l)#和集合(k,lに含まれる要素全て)
[1] 1 2 3 4 5 6 7 8 9 10 12 14 16 18 20
> setdiff(k,l)#差集合(kに含まれるものから、lにも含まれるものは除く)
[1] 1 3 5 7 9
> intersect(k,l)#積集合(k.l両方に含まれているもの)
[1] 2 4 6 8 10
繰り返しのfor文
C言語やjavaなど他のプログラミング言語を勉強したことがあるなら、必ず知っているであろう、for文とif分はRでも使えます。書き方がほかの言語と少し違うので注意が必要です。
for文というのは繰返し文です。プログラムを見てみましょう。
for(i in 1:10){
ans = ans +1
}
このプログラムの意味は、
iに1を代入、for分の中身を実行し、終わったらiに2を代入してfor分の中身を実行。終わったら今度はiに3を代入してfor分の中身を実行、、、。これを繰り返し、iに10を代入してfor分の中身を実行したら終了。
ということです。つまり、for分の中身のプログラムを10回繰り返すプログラムです。これがRでのfor文の書き方なので覚えておきましょう。ちなみにansの中身はこうなります。
[1] 10
もともと0が入っていたansに1を10回足したので、10になりました。
条件式のif文
Rにはif文というのも用意されています。条件式を書き、条件式が真(TRUE)の時のみif分の中身を実行します。プログラムを見てみましょう。
> if(ans == 0){
+ ans = ans+1
+ }
> ans
[1] 1
条件式は真であるので、if分の中身が実行され、ansは1が足されました。
> if(ans == 100){
+ ans = ans + 1
+ }
> ans
[1] 0
条件式は真ではない(FALSE)のでif文の中身は実行されず、スルーされました。当然ansの値にも変化はありません。
その他数々の便利コマンド
Rには、ほかにも便利コマンドがたくさんあります。もちろん、すぐ覚える必要はありません。動作確認だけしてみましょう。
mean(b)#平均
var(b)#分散
sd(b)#標準偏差
median(b)#中央値
sum(b)#合計値
max(b)#最大値
min(b)#最小値
rev(b)#ベクトルを逆順にする。
order(b)#ベクトルの要素を小さい順に見たときに、何番目なのかを出力
sort(b)#ベクトルを小さい順に並べる。(昇順と言う)rev(sort(b))#組み合わせて使えばベクトルを降順に並べることも可能
まとめと復習用コピペプログラム
いかがでしたでしょうか。今回学んだのは、Rで解析をする上で、大切なテクニックです。しかし、もちろん、今すぐに全てを覚える必要はありません。こんなのもあるんだ、ということを頭の片隅に置いておきましょう。今後解析をしていく上で、また困ったりしたらここに戻ってきてください。今回使ったプログラムの全文です。コピペ実行で確認してみてください。
#データ読み込み
df <- read.csv("sample-data.csv",header=T,row.names=1)
#便利なコマンドnrow(df)#dfの行数
ncol(df)#dfの列数table(df$性別)
table(df$性別,df$病気)
#tableは要素のカウントをするcolnames(df)
rownames(df)
#colnames, rownamesはデータの行名、列名を見る
#見たいデータが行列ではなく、ベクトルのときは行、列は関係ないのでnames()を使う
numeric(15)#0を15個並べる
rep(0,15)#0を15回繰り返すda <- 12345
da.ch <- as.character(da)#daを文字列に変換
da <- as.numeric(da.ch)#da.chを数字に変換is.character(da)#daが文字列型ならTRUE
is.numeric(da)#daが数字型ならTRUE
is.numeric(da.ch)#da.chが数字型ならTRUE
#as.~は型変更、is.~は型確認(numeric,character,vector,matrix,data.frameで使われる)y <- c(NA,1,2,NA,5)
is.na(y)#NAかどうかを調べる
na.omit(y)#欠損(NA)を除くz <- c(2,4,6,1,3,5)
length(z)
#lengthはベクトルの長さを測るa <- c(1,2,3,1,2,3,1,2,3)
unique(a)
#uniqueは重複する要素を除いたベクトルを返す
k <- 1:10
l <- seq(2,20,by=2)
k
l
union(k,l)#和集合(k,lに含まれる要素全て)
setdiff(k,l)#差集合(kに含まれるものから、lにも含まれるものは除く)
intersect(k,l)#積集合(k.l両方に含まれているもの)#for文とif文
ans <- 0
for(i in 1:10){
ans = ans +1
}
ansans <- 0
if(ans == 0){
ans = ans+1
}
ans
ans <- 0
if(ans == 100){
ans = ans + 1
}
ans
b <- c(1,4,5,3,7,8,9,9,2,5)
mean(b)#平均
var(b)#分散
sd(b)#標準偏差
median(b)#中央値
sum(b)#合計値
max(b)#最大値
min(b)#最小値
rev(b)#ベクトルを逆順にする。
order(b)#ベクトルの要素を小さい順に見たときに、何番目なのかを出力
sort(b)#ベクトルを小さい順に並べる。(昇順と言う)
rev(sort(b))#ベクトルを降順に並べる。
【第1回】ベクトル・行列の作成と四則演算・要素の参照
【第2回】データ読み込みとデータの取り出し方
【第2.5回】Rで解析する上で知っておきたい便利なコマンド集 ←今ここ!!
【第3回】Rで線形モデルによる回帰分析
【第4回】Rでの自作関数の作り方・使い方
【第5回】グラフのプロットと画像保存の方法(回帰直線)【終】
※R言語入門のトップページはこちら








Recommended